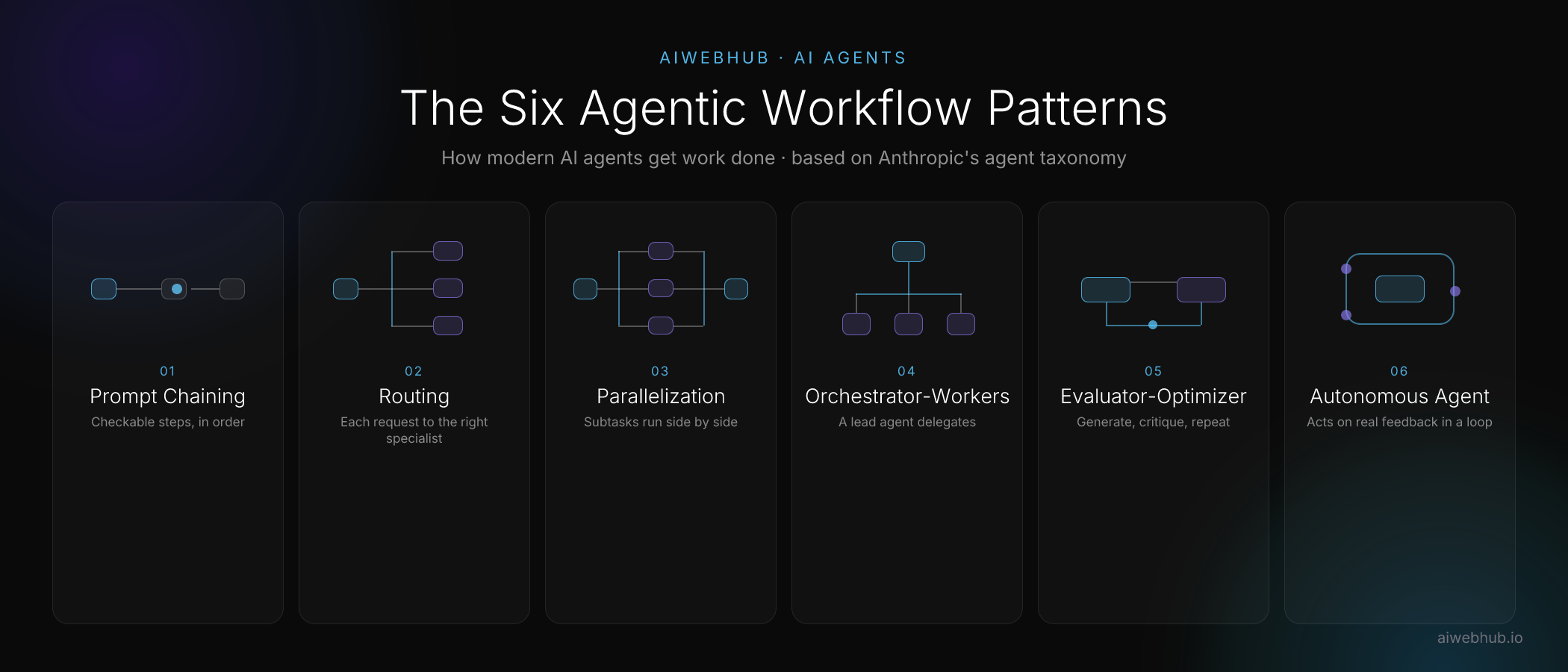
Agentic workflow patterns are the repeatable design structures that determine how an AI agent breaks down a task, decides what to do next, and combines the results into a reliable answer. They are the difference between an AI demo that looks impressive once and a system you can actually trust to handle real customer work every day. In late 2024, Anthropic — the company behind the Claude family of models — published the clearest public taxonomy of these patterns, and the same six structures now underpin most production AI agents in 2026. This guide explains each pattern in plain terms, shows where it fits, and covers what the research says about when the added complexity is worth the cost.
What Are Agentic Workflow Patterns?
An agentic workflow pattern is a proven way of arranging large language model calls, tools, and data so a system produces consistent results on a specific class of task. Every pattern builds on the same foundation Anthropic calls the augmented LLM: a language model enhanced with three capabilities — retrieval to pull in relevant data, tools to take real actions through APIs, and memory to hold context across steps. Strip those away and you have a chatbot. Add them and you have the raw material for an agent.
From there, Anthropic draws a sharp line between two categories. Workflows are systems where language models and tools are orchestrated through predefined code paths, meaning the developer decides the sequence of steps in advance. Agents are systems where the model dynamically directs its own process and tool usage, deciding for itself how to accomplish the task. Workflows trade flexibility for predictability and lower cost. Agents trade predictability for the ability to handle open-ended problems. Knowing which category a problem calls for is the first real decision in any build, and getting it wrong is one of the most common reasons agent projects stall before launch.
Prompt Chaining: Breaking a Task Into Checkable Steps
Prompt chaining decomposes a task into a fixed sequence of steps, where each model call works on the output of the one before it. Instead of asking a single prompt to do everything at once, you split the job — draft, then refine, then format — so each step is simpler and more accurate than a single overloaded request could ever be.
The real power of prompt chaining is the gate: a programmatic check placed between steps that verifies an intermediate result before the chain continues. If a generated outline fails to meet your criteria, the system catches it immediately rather than compounding the error three steps later. Anthropic's own example is writing a document outline, checking that outline against specific requirements, and only then writing the full document.
For business use, prompt chaining suits any task with a clear, ordered structure — generating a product description and then translating it into three languages, or drafting a customer email and then checking it against your brand guidelines before it sends. It is predictable, straightforward to debug, and cheap to run, which makes it the right starting point for a surprising number of real problems.
Routing: Sending Each Request to the Right Specialist
Routing classifies an incoming request and directs it to a specialized follow-up task built for that specific category. Rather than forcing one general prompt to handle every situation, a router first reads the request, decides what type it is, and hands it to the prompt, tool, or even the model best suited to it.
A customer-service agent is the clearest example. A refund request, a technical troubleshooting question, and a pre-sales inquiry each need different knowledge, tone, and actions. Routing sends each one down its own path, which keeps every individual prompt focused and accurate instead of bloated and mediocre at everything.
Routing is also a powerful cost lever. It lets you use a smaller, cheaper model for simple, high-volume queries and reserve a more capable model for the complex cases that genuinely need it. In our experience building business agents, routing is often the single change that turns an unreliable catch-all bot into something a company is comfortable putting in front of real customers.
Parallelization: Running Subtasks Side by Side
Parallelization runs multiple model calls at the same time and combines their outputs programmatically. It comes in two distinct forms. Sectioning splits a task into independent subtasks that run simultaneously — for example, having separate calls analyze a contract's pricing, liability, and termination clauses in parallel, then merging the findings. Voting runs the same task several times to get diverse outputs, then aggregates them, which is useful when you want multiple perspectives or a confidence signal before trusting a result.
The benefits are speed and reliability. Independent subtasks finish in the time of the slowest one rather than the sum of them all, and voting catches mistakes that a single pass would quietly miss. A content-moderation system might run several checks in parallel — one for tone, one for policy violations, one for unsupported factual claims — and only approve content that clears every one of them. When accuracy matters more than squeezing out the last bit of cost, parallelization is one of the most effective patterns available, and it is the engine that makes the multi-agent systems below so fast.
Orchestrator-Workers: A Lead Agent That Delegates
Orchestrator-workers is the pattern behind most serious multi-agent systems. A central lead model — the orchestrator — dynamically breaks a complex task into subtasks, delegates each one to a worker model, and then synthesizes their results into a single coherent answer. The defining feature is that the subtasks are not fixed in advance. The orchestrator decides what they are based on the specific input, which is exactly what separates this pattern from ordinary parallelization.
Anthropic uses this structure in its production research system. A lead agent powered by Claude Opus 4 analyzes the query, develops a strategy, and spawns three to five worker agents powered by Claude Sonnet 4 to investigate different angles at the same time. Each worker runs its own searches, evaluates what it finds, and reports its findings back. The orchestrator then decides whether the picture is complete or whether more digging is needed before handing off the final synthesis. This is how a single request becomes a coordinated investigation rather than one model guessing in isolation, and it is the closest thing in agent design to running a small research team.
Evaluator-Optimizer: Built-In Quality Control
Evaluator-optimizer puts two model roles in a loop: one generates a response while the other evaluates it against criteria and sends back specific, actionable feedback, which the generator then uses to improve. The cycle repeats until the output meets the bar. It is the closest thing in agent design to having a built-in editor who never gets tired.
This pattern shines whenever there are clear evaluation criteria and iterative refinement measurably improves the result. Translating text where nuance and tone matter, writing code that has to pass a defined set of tests, or producing a sales proposal that must hit specific points all benefit from a second model whose only job is to find what is wrong with the first model's work. The trade-off is cost and latency, because every loop is another round of model calls. But for high-stakes output where a mistake is expensive to ship, the extra passes are usually worth it — and far cheaper than a customer catching the error after the fact.
The Autonomous Agent Loop: Acting on Real Feedback
The autonomous agent is the pattern most people picture when they hear the term AI agent. After an initial command or conversation with a person, the agent plans and operates on its own. It is, in Anthropic's own words, simply a language model using tools based on environmental feedback in a loop. It acts, observes what actually happened, and decides its next move without a human scripting each step along the way.
What makes this work, and what makes it dangerous when done poorly, is ground truth. At every step the agent must get real feedback from the environment — an actual tool result, a real code execution, a genuine API response — rather than trusting its own assumptions about what probably happened. An agent that books appointments checks the live calendar before it confirms anything. An agent that writes code runs that code and reads the errors. This grounding is the entire difference between an agent that catches and corrects its own mistakes and one that confidently compounds them. It is also why the autonomous loop demands the most rigorous testing of any pattern before it ever touches a paying customer.
What Multi-Agent Orchestration Actually Buys You
Combining these patterns into a full multi-agent system delivers real, measured gains — but not for free, and the honest numbers matter more than the hype. When Anthropic compared its multi-agent research system against a single agent on the same evaluation, the multi-agent setup outperformed the single agent by 90.2 percent. The parallelization built into the orchestrator-workers pattern cut research time on complex queries by up to 90 percent, because three to five workers investigate simultaneously instead of one model grinding through everything in sequence.
The cost side is just as specific, and just as important to understand before you commit. Anthropic found that token usage alone explains roughly 80 percent of the performance variance on these tasks — in plain terms, the systems that do more thinking simply perform better. But that thinking is expensive. A single agent uses about four times the tokens of a normal chat interaction, and a multi-agent system uses roughly fifteen times as many. That fifteen-times multiplier is the reason multi-agent orchestration is not the right answer for every problem. It earns its place only on high-value tasks where the quality gain clearly justifies the spend.
Choosing the Right Agentic Workflow Patterns for Your Business
The most important lesson from Anthropic's research is also the most counterintuitive: complexity is a cost, not a feature. The explicit guidance is to start with the simplest approach that works and add structure only when it demonstrably improves the outcome. Most business problems do not need a fifteen-times-cost multi-agent system. A well-built routing or prompt-chaining workflow handles the majority of real customer-service and operations use cases reliably and cheaply.
Use a simple workflow pattern when the task is well-defined and the steps are predictable — order status lookups, FAQ handling, lead qualification, appointment booking. Reach for orchestrator-workers or the full autonomous loop only when the task genuinely requires open-ended investigation or decisions that cannot be scripted in advance. As we explained in our guide to what AI agents are and how they help businesses in 2026, the gap between a useful agent and a frustrating one usually comes down to disciplined design rather than raw model power, and the same principle governs which pattern you choose.
The market is moving in this direction quickly. Gartner projects that 40 percent of enterprise applications will feature task-specific AI agents by 2026, up from less than 5 percent in 2025. But Gartner also predicts that more than 40 percent of agentic AI projects will be canceled by the end of 2027 — and many of them will be killed by exactly the mistake of reaching for complexity the problem never required. Choosing the right pattern is not a technical detail. It is the difference between a project that ships and one that quietly gets shut down.
Ready to Put AI Agents to Work?
Understanding these patterns is the first step. Applying the right one to your specific business is where the value is actually created, and where most projects go wrong. At AIWebHub, we build custom AI agents on these proven patterns, starting with the simplest structure that solves the problem and adding orchestration only where it earns its keep. Each agent is quoted to scope, typically a one-time build plus a monthly fee for hosting, monitoring, and ongoing tuning, and that includes the discovery work to choose the right pattern from the very start.
If you are exploring how an AI agent could handle customer support, sales, scheduling, or internal automation for your business, visit our services page at aiwebhub.io/services to see what each plan includes, or read more about the fundamentals in our guide to what AI integration means for your business. When you are ready to move, contact us at aiwebhub.io/contact for a free consultation and a quote tailored to your specific use case. The businesses that win with AI in 2026 will not be the ones with the most complex systems. They will be the ones who matched the right pattern to the right problem.
